728x90
- 모듈 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline- 데이터 불러오기
boston = pd.read_csv("data/boston_missing.csv")- 데이터 shape 확인
boston.shape
# (506, 20)- 데이터 column 확인
boston.info()
- 요약 통계량 확인
* describe() 함수를 사용
* 수치형 변수에 관해서만 결과를 보여준다
* 결측치는 제거하고 계산해준다
boston.describe()
- 상관분석
* 수치형 변수중에서 각각 2개의 column씩 상관관계를 보여준다
* 값은 -1 ~ 1사이에서 존재한다
* 절대값이 0.7이상이면 둘 사이의 관계가 밀접하게 관련이 되어있다고 볼 수 있다
* 둘 사이의 관계가 높다고 인과관계로 잘못 해석하면 안 된다
boston.corr()
# 상관관계 시각화
# seaborn모듈 안 heatmap함수를 통해서 구현 가능
# data : corr()함수를 통해 나온 결과
# annot : default는 False / True로 설정하면 해당 필드에 값을 보여줌
# fmt : 값 소숫점 표현
# cmap : 그라데이션 색깔 설정
# Greys', 'Purples', 'Blues', 'Greens', 'Oranges', 'Reds', 'YlOrBr', 'YlOrRd', 'OrRd', 'PuRd', 'RdPu', 'BuPu','GnBu', 'PuBu', 'YlGnBu', 'PuBuGn', 'BuGn', 'YlGn'
# 'PiYG', 'PRGn', 'BrBG', 'PuOr', 'RdGy', 'RdBu', 'RdYlBu', 'RdYlGn', 'Spectral', 'coolwarm', 'bwr', 'seismic'
plt.figure(figsize=(12,12))
sns.heatmap(data = boston.corr(), annot=True, fmt = '.1f', cmap='Purples')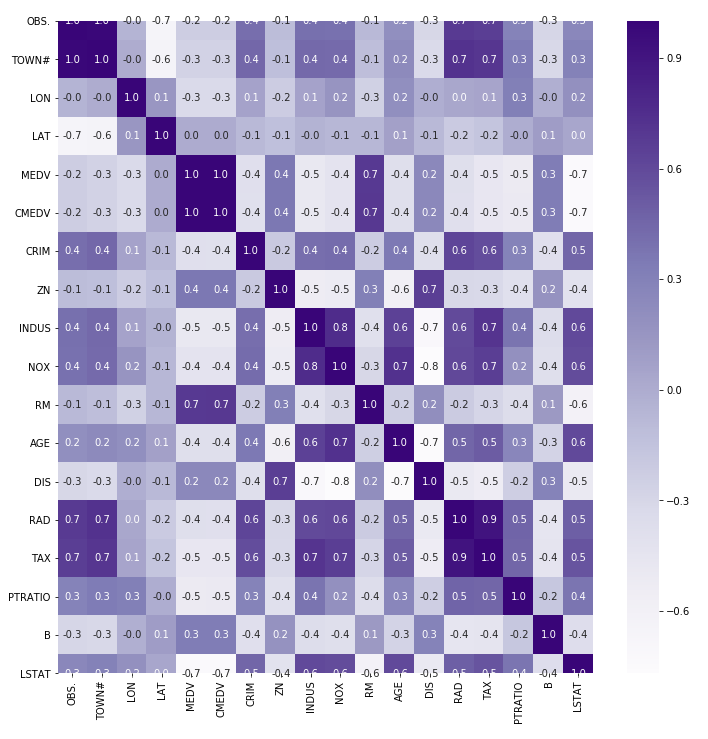
- 결측치 처리
결측치란 해당 필드에 값이 존재하지 않은것을 의미
1) 결측치의 숫자가 매우 적다면 이들을 삭제하고 분석
2) 결측치의 숫자가 어느정도 존재하면 값을 대체
# NA 확인
na_dic={'index': list(range(0, boston.shape[1])),
'column type': boston.dtypes,
'null values(num)': boston.isnull().sum(),
'null values(%)': boston.isnull().sum() / boston.shape[0] * 100}
na = pd.DataFrame(na_dic).T
# CMEDV column은 제거
boston.drop(['CMEDV'], axis=1, inplace=True)# MEDV는 중위 값으로 대체
boston_median = boston.MEDV.describe()['50%']
boston['MEDV'].fillna(boston_median, inplace=True)# CHAS 6개 값을 제거
boston = boston[boston.CHAS.notnull()]- 이상치 처리
* 이상치란 기존 데이터들로부터 동떨어진 데이터
* 측정오류나 잘못된 입력으로 인해 이상치가 포함될 수 있음
* 이상치가 포함된 데이터로 만든 모델은 정확한 결과를 낼 수 없으며 신뢰도가 떨어짐
* 주로 boxplot을 통해서 판단
# boxplot 시각화
sns.catplot(x='CHAS', y="MEDV", kind='box', data=boston)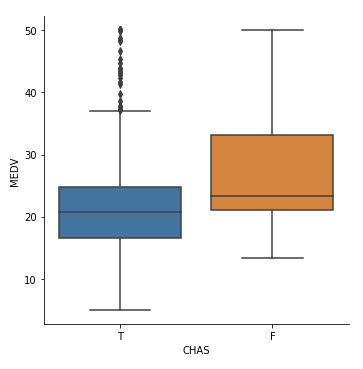
# 결측치 제거
temp = boston[boston.CHAS == 'T'].describe()['MEDV']['75%']
temp2 = boston[(boston.CHAS == 'T') & (boston.MEDV > temp)]
boston[~boston.index.isin(temp2.index)]- 데이터 표준화 / 정규화
# NOX, AGE column 불러오기
boston2 = boston[['NOX', 'AGE']]from sklearn.preprocessing import StandardScaler
# scaler 생성
standard_scaler = StandardScaler()
# scaler 학습
standard_scaler.fit(boston2)
# scaler 적용
boston_scaled = standard_scaler.transform(boston2)
# 최종 데이터프레임 만들기
pd.DataFrame(boston_scaled, columns=boston2.columns)
from sklearn.preprocessing import MinMaxScaler
# scaler 생성
min_max_scaler = MinMaxScaler()
# scaler 학습
min_max_scaler.fit(boston2)
# sclaer 적용
boston_scaled = min_max_scaler.transform(boston2)
# 최종 데이터프레임 만들기
pd.DataFrame(boston_scaled, columns=boston2.columns)
728x90
'데이터분석' 카테고리의 다른 글
| RMSE, Grid Search python 구현 (0) | 2020.11.12 |
|---|---|
| Logistic Regression (0) | 2020.11.12 |
| seaborn 시각화 python (0) | 2020.11.12 |
| python 복사 단순 객체복사 vs shallow copy vs deep copy (0) | 2020.10.19 |
| Python fire package (0) | 2020.10.19 |

댓글